
「Webスクレイピングを手軽に始めたい」「特別なツールを使わずにデータ収集を自動化したい」とお考えではありませんか?
本記事では Google Apps Script(GAS) を使い、Googleスプレッドシートと連携したWebスクレイピングの方法を詳しく解説します。
初心者でも簡単にWebスクレイピングを始められるので、ぜひ参考にしてください!
Webスクレイピングとは
Webスクレイピングは、Webサイトから特定のデータを抽出する技術です。
データ収集作業を自動化し、効率的に分析や運用に活用することができます。
本記事では、Google Apps Script(GAS) を使ってWebスクレイピングを行います。
WebスクレイピングにGASを使用するメリットは、
- 無料で利用可能:Googleアカウントがあれば無料で利用可能
- スプレッドシートとの連携可能:データを簡単に直接保存・操作可能
- 環境構築不要:ブラウザ上で完結するため、環境構築の手間がなく手軽に実行可能
があります。
それでは、実際にGASを使用して、Webスクレイピングしていきます。
サンプルプロジェクトの準備
今回のサンプルでは、スプレッドシートのA列に入力されたURLをもとに、各ページの「タイトル」と「メタディスクリプション(説明)」を取得します。
そのデータを、それぞれスプレッドシートのB列とC列に書き込む仕組みを作成します。
まずは、スプレッドシートに操作するデータを用意します。
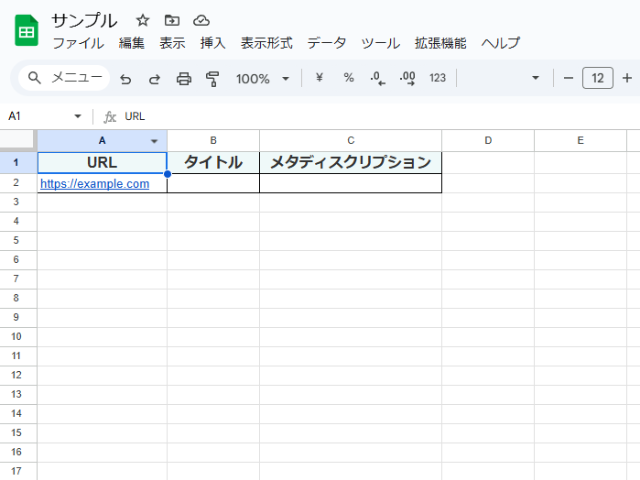
今回は、以下のサンプルデータをスプレッドシートのA1:C2セルの範囲に入力します。
| URL | タイトル | メタディスクリプション |
|---|---|---|
| https://example.com |
そして、GASスクリプトの実装をしていきます。
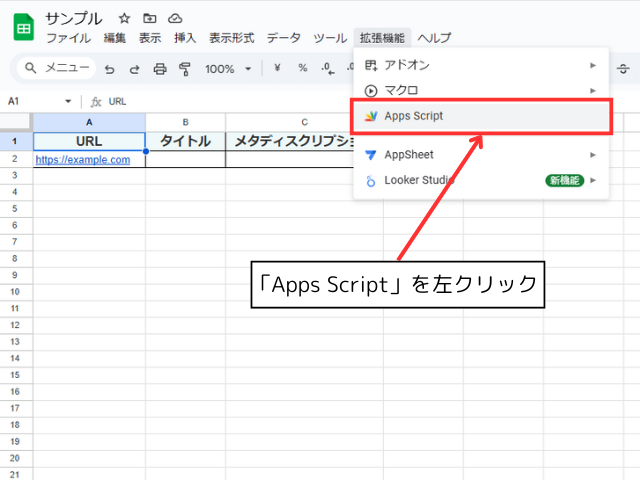
Googleスプレッドシートのメニューバーの「拡張機能」を左クリックし、「Apps Script」を選択します。
「Apps Script」を選択すると、スクリプトエディタが新しいタブで開きます。
新しいタブでスクリプトエディタが開かれたら、WEBスクレイピングのスクリプトを作成します。
以下のスクリプトをコピーして貼り付け、プロジェクトを保存します。
サンプルスクリプト
function scrapeData() {
// 現在開いているスプレッドシートを取得
const sheet = SpreadsheetApp.getActiveSpreadsheet().getActiveSheet();
const data = sheet.getDataRange().getValues();
for (let i = 1; i < data.length; i++) {
const url = data[i][0];
if (url) {
try {
// 指定したURLからHTMLデータを取得
const response = UrlFetchApp.fetch(url);
const html = response.getContentText();
// タイトルを抽出
const title = html.match(/<title>(.*?)<\/title>/i)?.[1] || "No Title";
// メタディスクリプションを抽出
const description = html.match(/<meta name="description" content="(.*?)"/i)?.[1] || "No Description";
// 結果をスプレッドシートに書き込む
sheet.getRange(i + 1, 2).setValue(title);
sheet.getRange(i + 1, 3).setValue(description);
} catch (e) {
sheet.getRange(i + 1, 2).setValue("Error");
sheet.getRange(i + 1, 3).setValue(e.message);
}
}
}
}【補足】タイトルとメタディスクリプション抽出の正規表現について
今回のサンプルスクリプトでは、WebページのHTMLから「タイトル」と「メタディスクリプション」を抽出するために、正規表現を使用しています。
正規表現について詳しく知りたい方は、こちらをご覧ください!

1.タイトルの抽出に使用した正規表現
const title = html.match(/<title>(.*?)<\/title>/i)?.[1] || "No Title";上記のコードでは、<title>タグに囲まれた内容を抽出し、該当データがない場合は"No Title"を返すようになっています。
正規表現/<title>(.*?)<\/title>/iは、以下の構造になっています。/:正規表現の開始と終了を示します。():タグの中身を取得.*:改行を除く、任意の文字に0回以上繰り返しマッチ?:最初に見つかった終了タグまでの範囲でマッチ<\/title>:スラッシュはエスケープ(\)が必要i:大文字小文字を区別しない
2.メタディスクリプションの抽出に使用した正規表現
const description = html.match(/<meta name="description" content="(.*?)"/i)?.[1] || "No Description";上記のコードでは、<meta>タグのname="description"かつcontent属性の値を抽出し、該当データがない場合は"No Description"を返すようになっています。
正規表現/<meta name="description" content="(.*?)"/iは、以下の構造になっています。/:正規表現の開始と終了を示します。<meta name="description":HTMLの<meta>タグで、name属性がdescriptionの部分を特定content="(.*?)":content属性の値を取得i:大文字小文字を区別しない
サンプルプロジェクトの実行結果
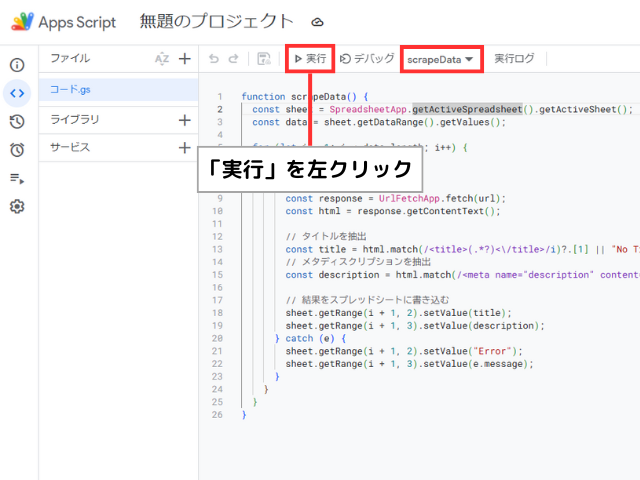
まず、サンプルスクリプトを実行します。
スクリプトエディターのメニューバーで「scrapeData」が選択されていることを確認し、「実行」ボタンを左クリックします。
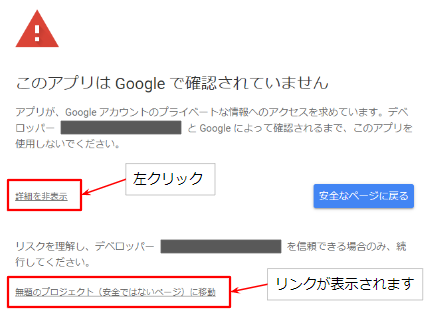
初めて実行する際には、スクリプトに対する権限の承認が求められる場合がありますので、承認してください。
「このアプリは Google で確認されていません」と表示された場合は左下の詳細をクリックすると、「無題のプロジェクト(安全ではないページ)に移動」というリンクが表示されます。
このリンクをクリックすると次のページへ遷移できます。
続いて、スクリプトの実行結果を確認します。
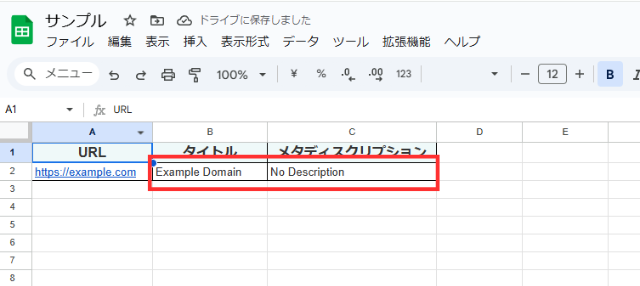
スクリプトが正常に実行されると、B列C列に「タイトル」「メタディスクリプション」が入力されます。
今回はスクリプトを実行した結果、B列に「Example Domain」、C列にメタディスクリプションが見つからなかった場合に入力される「No Description」が入力されており、Webスクレイピングできていることが確認できます。
WEBスクレイピングの注意点
1.サイトの利用規約を確認し、スクレイピングが許可されているかを確認してください。
2.過剰なリクエストを送らないように、適切な実行間隔に調整してください
まとめ
GASを使えば、初心者でも簡単にWebスクレイピングを始めることができます。
今回のサンプルをベースに、ぜひご自身のプロジェクトに応用してみてください!


コメント